
 Building a bridge between bench and computer science
Building a bridge between bench and computer science
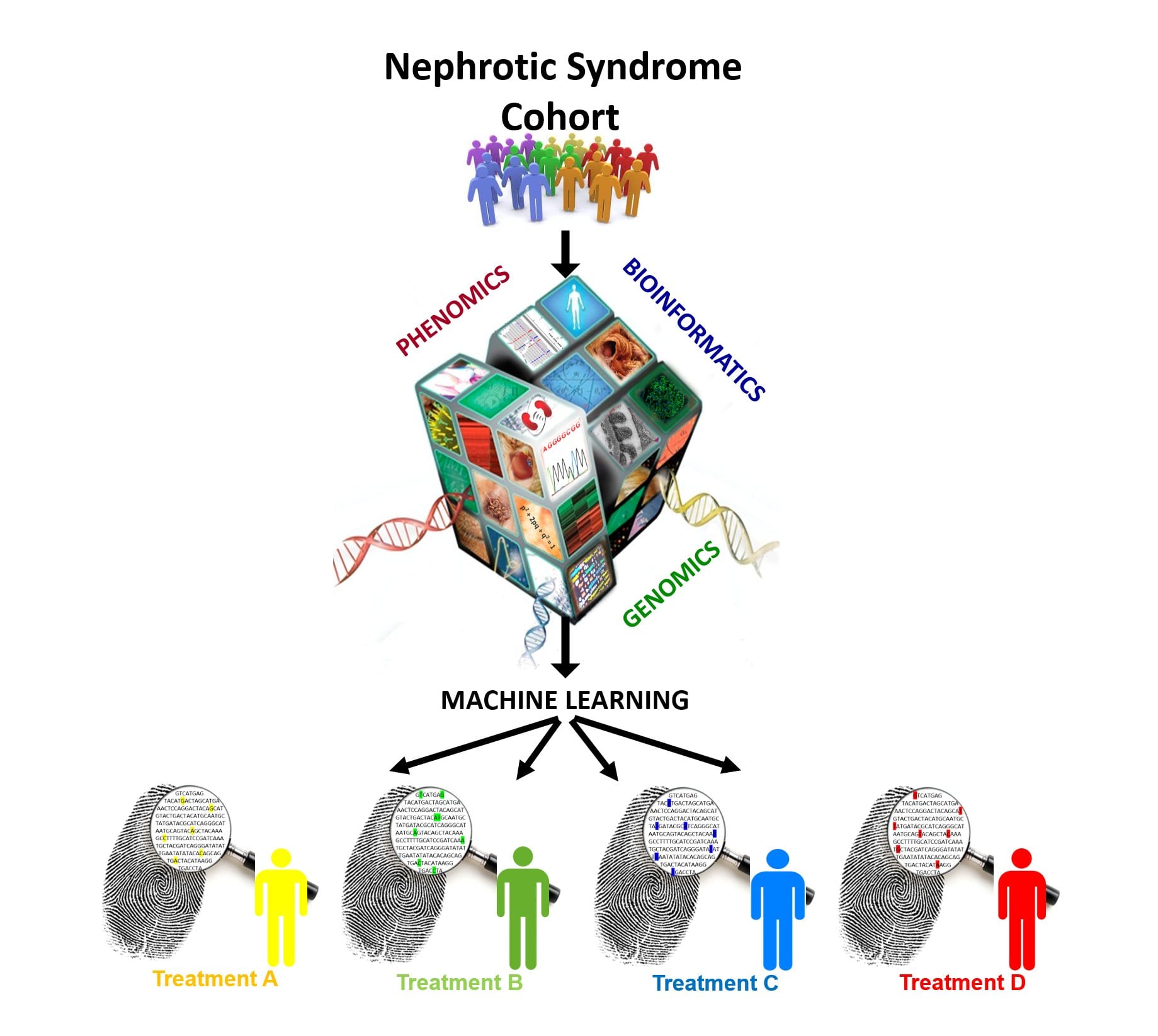
This project begins a new interdisciplinary collaboration between renal biology and engineering mathematics to apply novel machine learning methods to investigate genetic signatures in a highly phenotyped rare kidney disease cohort.
Idiopathic Nephrotic Syndrome (INS) is a rare and one of the most difficult renal diseases in children and adults with the central event being glomerular podocyte injury. Up to 30% of steroid resistant NS cases are caused by a single-gene defect. The rest are considered to be immunologically mediated and caused by an as yet unidentified circulating factor(s) and can present as secondary steroid resistance after initial steroid sensitivity. There are currently no robust or reliable clinical indicators or biomarkers of response meaning that prediction of disease progression or response to medication cannot be clearly defined. The impact of genetic architecture in acquired disease is completely unknown.
Our aim is to understand the genetic architecture of acquired nephrotic syndrome and its impact on the disease course.
Pilot study
This is a pilot project with the aim of developing and using state of the art methods from bioinformatics and machine learning to classify subtypes of INS, potentially with different clinical outcomes, using whole exome and genome sequencing data.
We used exome sequencing data from the deeply phenotype UK cohort of paediatric INS patients. We investigated the differences in the enrichment of single nucleotide variations in different INS phenotypes. Since ~70% of patients are likely to have immunologically mediated cause of INS, we focused on genes not only known to be involved in INS but also B-cell, T-cell and lymphocyte genes.
Key objectives achieved
- Hierarchical clustering pointed out significant enrichment of certain INS phenotypes in specific clusters which were based on the proportion of genetic variations in the selected genes. Thus indicating a potential corresponding genetic signature for each INS phenotype, which can be now investigated further
- Results from this preliminary project were used for a KRUK fellowship application which was successful.
Looking ahead
- Extend our investigation genome-wide (all genes instead of a tiny subset)
- Tease out the influential genes and/or variants
- Stratify INS patients into sub-types with corresponding genetic fingerprints/signatures
- Predict best treatment options based on the patients’ genotype.
Blog written by Agnieszka Bierzynska, Bristol Medical School & Mark Rogers, Engineering Maths at the University of Bristol.
This project was funded by the Jean Golding Institute Seed Corn Funding Scheme 2018. To find out about other projects supported by this scheme, take a look at the Jean Golding Institute Projects.