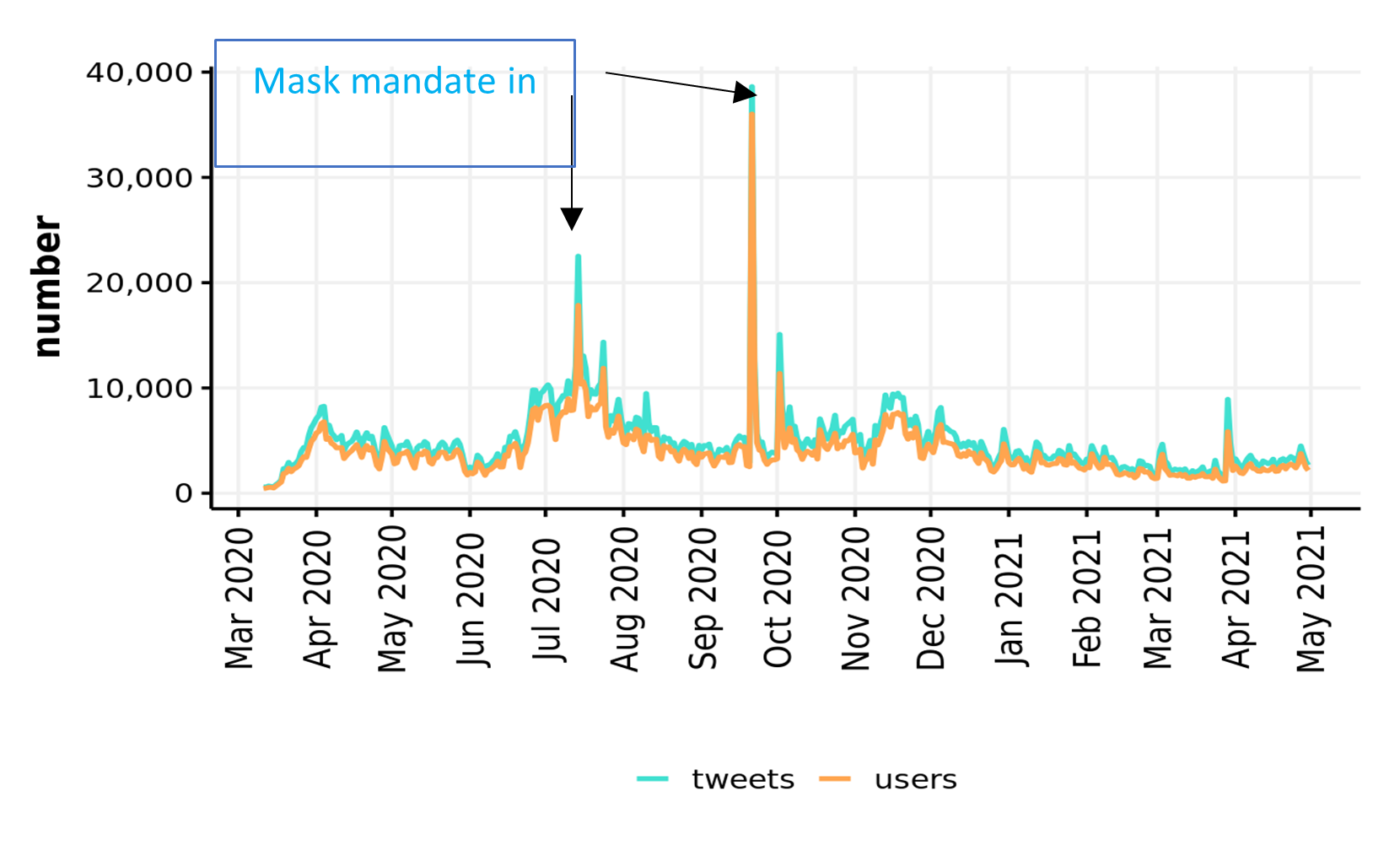
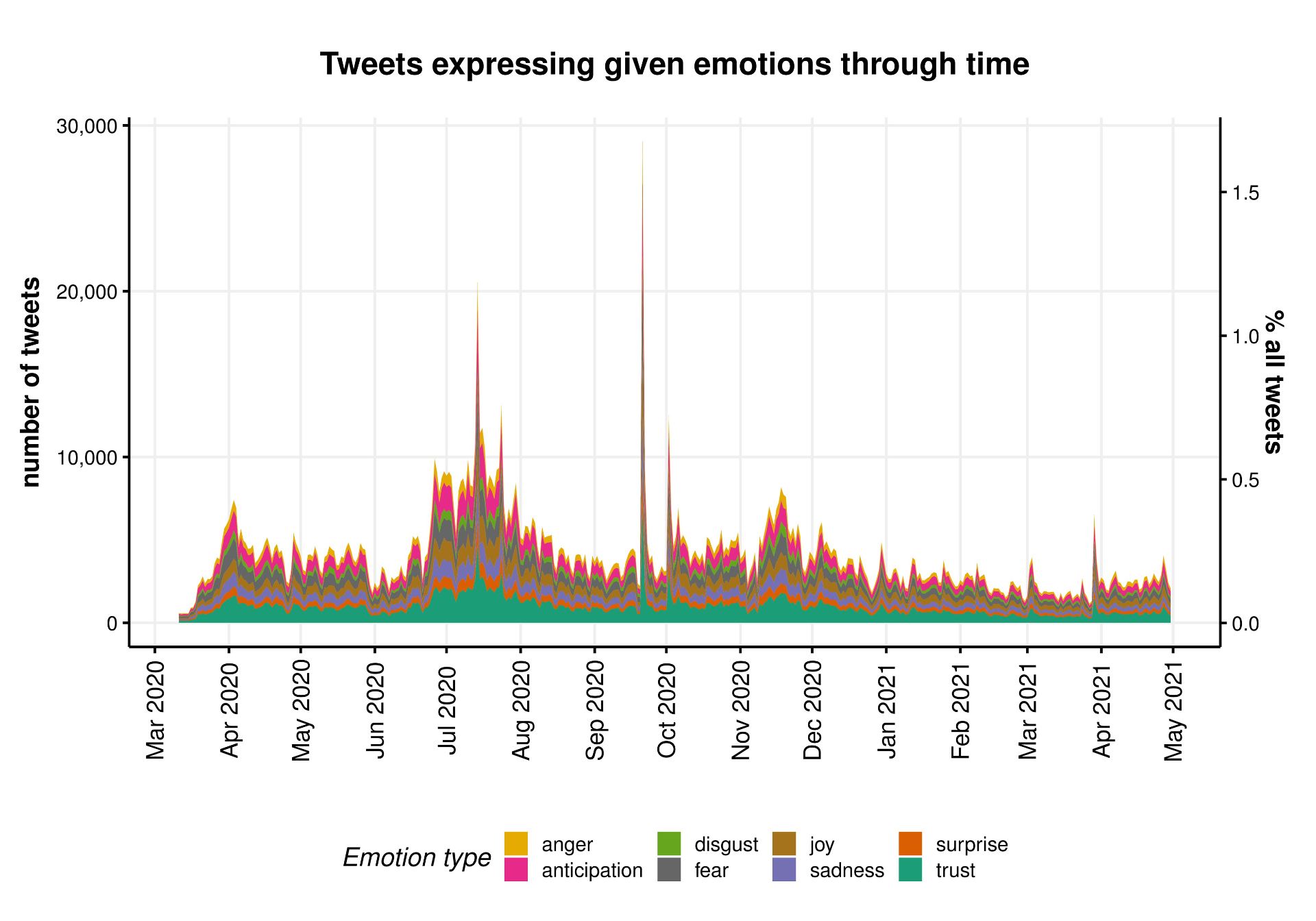
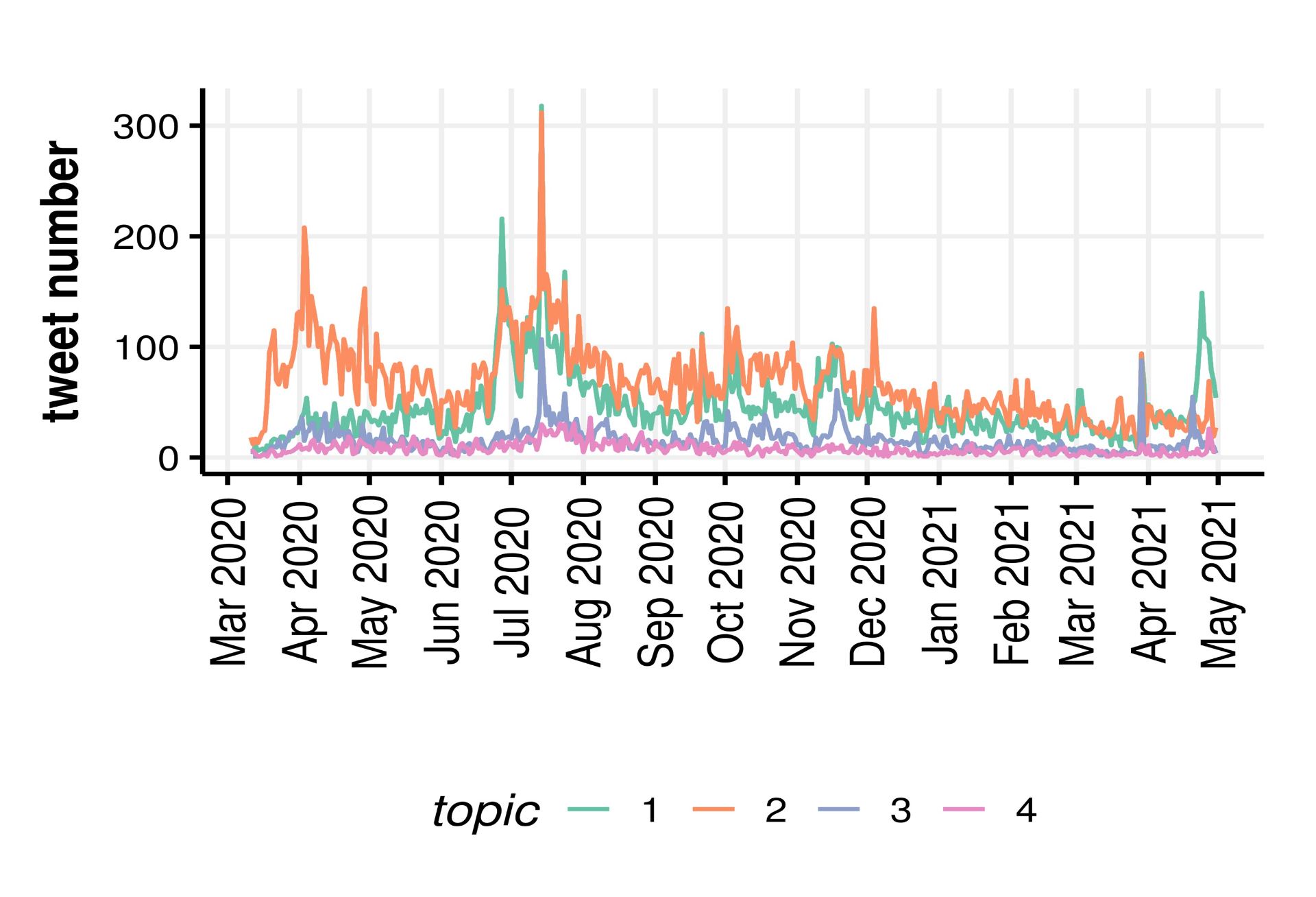
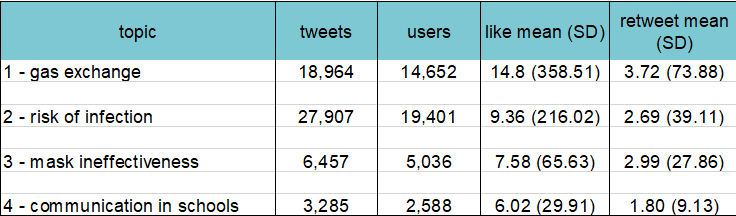
Much of the global infrastructure is now operating well outside its designed lifetime and usage. New technology is needed to allow the continued safe operation of this infrastructure, and one such technology is the ‘Digital Twin’.
A Digital Twin for Infrastructure
A Digital Twin is a mathematical model of a real object, that is automatically updated to reflect changes in that object using real data. As well as being able to run simulations about possible future events, a Digital Twin of a structure also allows the infrastructure manager to estimate values about the real object that cannot be directly measured. To deliver this functionality, however, the modelling software must be able to interface with the other components of the Digital Twin, namely the structural health monitoring (SHM) system that collects sensor data, and machine learning algorithms that interpret this data to identify how the model can be improved. Most commercial modeling software packages do not provide these application interfaces (APIs), making them unsuitable for integration into a Digital Twin.
A Requirement for Open Interfaces
The aim of this project was to create an ‘open-interface’ model of the Clifton Suspension Bridge (CSB), that will form one of the building blocks for an experimental Digital Twin for this iconic structure in Bristol (UK). Although structural models of the CSB exist, they are limited in both functionality and sophistication, making them unsuitable for use in a Digital Twin. For a Digital Twin to operate autonomously and in real-time, it must be possible for software to manipulate and invoke the structural model, tuning the model parameters based on the observed sensor readings.
The OpenSees finite element modeling (FEM) software was selected for the creation of the Digital Twin ready model, as it is one of the few pieces of open-source structural modeling software that has all the necessary APIs.
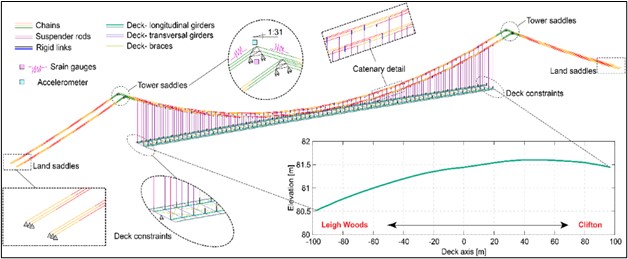
A finite element model of the Clifton Suspension Bridge, showing the relative elevation of the bridge deck and the length. Produced by Elia Voyagaki
Building the Model
Our seed corn funding has enabled the creation of an OpenSees-based FEM of the CSB. The information needed for this process has been gathered from a number of different sources, including multiple pre-existing models, to produce a detailed FEM of the bridge. The precise geometry of the CSB has been implemented in OpenSees for the first time, paving the way for the creation of a Digital Twin of Bristol’s most famous landmark.
Some validation of this bridge geometry has also been carried out. This validation has been done by comparing the simulated bridge dynamics with real world structural health monitoring data, collected from the CSB during an earlier project (namely the Clifton Suspension Bridge Dashboard). The dynamic behaviour of a bridge can be understood as being made up of many different frequencies of oscillation, all superimposed over one another. These ‘modes’ can be measured on the real bridge, and by comparing their shape and frequency with the simulated dynamics produced by the model it is possible to assess the model’s accuracy. Parameters in the model can then be adjusted to reduce the difference between the measured and modelled bridge dynamics. It is this process that can now be done automatically, thanks to the open interfaces between the model and the sensors’ data.
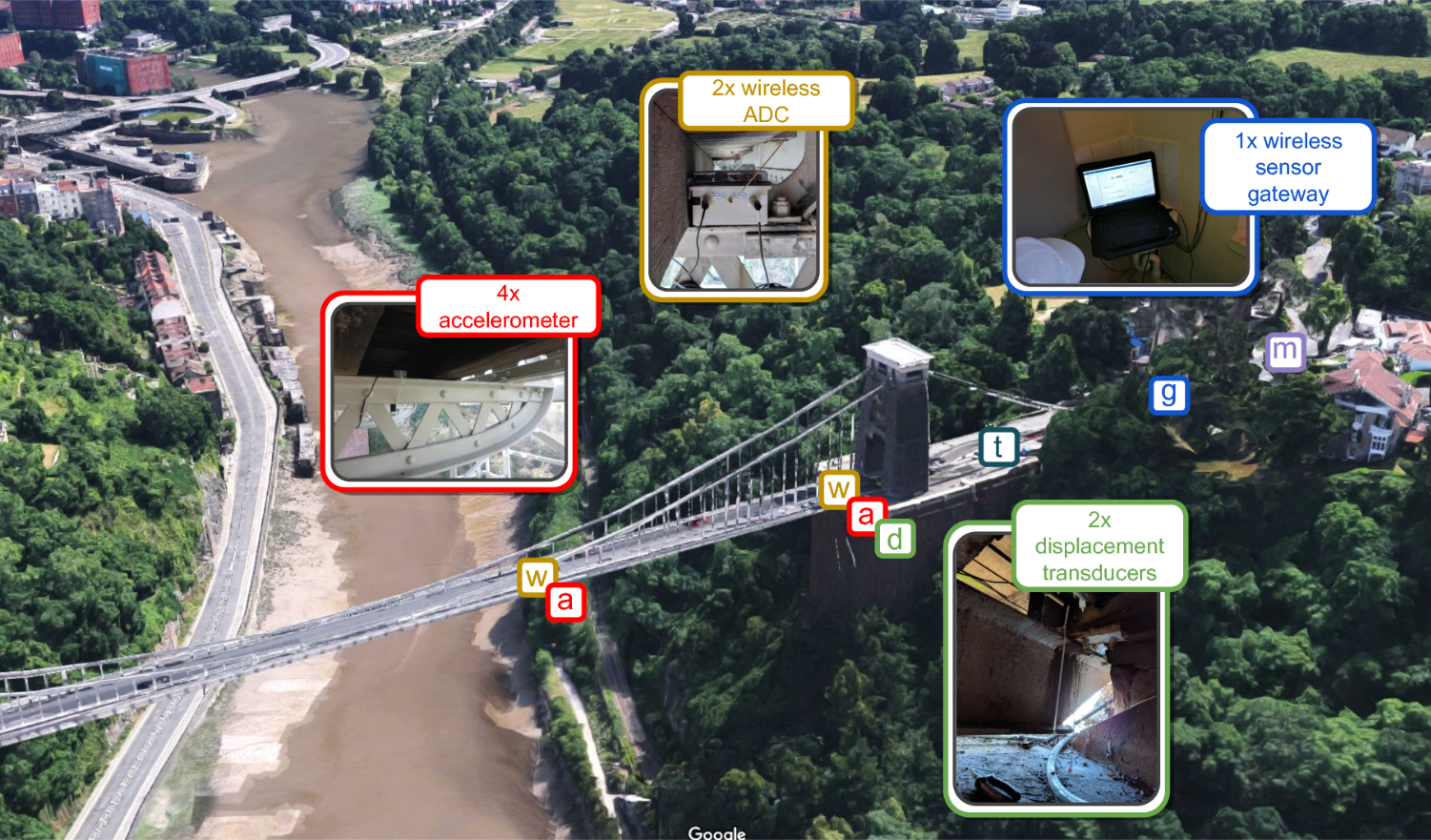
Illustration of the sensor deployment carried out as part of the Clifton Suspension Bridge Dashboard project. Base image from Google Maps.
Fitting the Pieces Together
The creation of this open-interface model will enable a new strand of research into Digital Twins, which will tackle some of the challenges that must be overcome before the technology can deliver insights to infrastructure managers. The CSB is currently being instrumented with a range of structural sensing infrastructure, turning it into a ‘living lab’ as part of the UKCRIC project’s Urban Observatories (UO) endeavour. The structural health monitoring system being developed for this living lab will also have all the APIs required for integration into a Digital Twin, providing access to both real-time and historic structural dynamics data, as well as information about the loading applied to the bridge through wind, vehicles and changes in temperature.
With both the sensing and modeling components of the Digital Twin developed, we will be in a position to start addressing the many technical challenges associated with automatic model updating. For example, modifying the model to match recorded data is an inverse problem, and with an FEM containing many thousands of different parameters there may be many different model configurations that match the observed sensor data. Developing an algorithm able to select the configuration that best represents the physics of the real object is a significant challenge, but this seed corn funding has allowed us to create a testbed that enables the scientific community to explore these challenges.
About Sam Gunner, the Author and PI on the project: Sam is an electronics and systems engineer within the Bristol UKCRIC UO team. He has developed and deployed distributed sensing systems for a range of different applications, from historic bridges to modern electric bicycles. As well as the technical changes involved in this, Sam’s research focuses on how technology can be used most effectively, to support these operational systems.
Email: sam.gunner@bristol.ac.uk
About Elia Voyagaki, a Co-I on the project: Elia is a PDRA with outstanding modelling experience who has previously worked with OpenSees. EV has a significant understanding of the structure of the Clifton Suspension Bridge thanks to her work on the CORONA project.
About Maria Pregnolato, a Co-I on the project: Maria is a Lecturer in Civil Engineering and EPSRC Research Fellow at the University of Bristol. Her projects within the Living with Environmental Change (LWEC) area investigate the impact of flooding on bridges and transportation.
Also involved in the Project, out Dr Raffaele De Risi, also involved in the project: Raffaele is a Lecturer in Civil Engineering. His research interests cover a wide range of academic fields, including structural reliability, engineering seismology, earthquake engineering, tsunami engineering, and decision-making under uncertainty.