Blog written by Rob Arbon, Alex Jones, George Holloway and Pete Bennett
This project was funded by the annual Jean Golding Institute seed corn funding scheme.
The JGI funded project “Metastable impressions” sought to bring together statistical modelling, sound engineering, classical composition and deep learning to create an audio-visual art work about the dynamics of proteins and their representations. The project grew out of work by PhD candidates Alex Jones and Rob Arbon (supervised by Dr Dave Glowacki) called ‘Sonifying Stochastic Walks on Biomolecular Energy Landscapes’. See also blog
The project team was comprised of Dr Pete Bennett (project supervisor), Alex Jones (sonification), Rob Arbon (animations and statistical modelling) and Dr George Holloway, Department of Ethnomusicology, Nanhua University, Taiwan (composition). We shall first give a more detailed overview of the project and then hear from Rob, George and Pete about their specific contributions and thoughts on the project.
All of the publicly available materials are available on our repository at the Open Science Framework.
Project overview
The core of this project is the Sonification: the process or turning information into sound. Take for example the popularity of the search term ‘Proteins’ on Google:
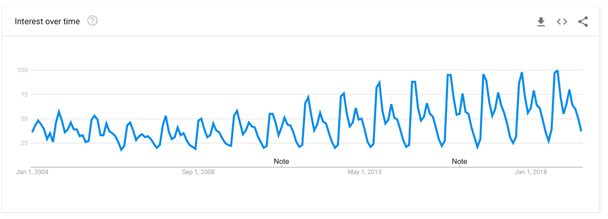
Here we map the popularity of the search term to the position of a blue dot in the vertical direction and the time that this relates to the position in the horizontal direction. In this way we make a visual display of the popularity over time. However, we could map the popularity to, say, the pitch of a piano sound and play them in the same order as the order they were observed in. This would result in an audio display (the other name for sonification) of the information, in this case the sound of a piano piece rising and falling in pitch over time.
The information that we wanted to sonify was a statistical model of protein, SETD8. The data for this protein came from the lab of John Chodera and was produced by Rafal Wiewiora. You can read about the amazing effort to produce this dataset in Computational ‘Hive Mind’ helps scientists solve an enzyme’s cryptic movements.
One criticism of sonification is that it is very hard to listen to for long periods of time so we decided to recruit a classically trained composer to help us design a sonification that would be pleasing to listen to. In order to help do this, the composer George Holloway composed the piece Metastable for string quartet which was performed by the Ligeti String Quartet in a performance event in May. The whole event (unfortunately including the ‘click track’ for the quartet only) was streamed on Twitter.
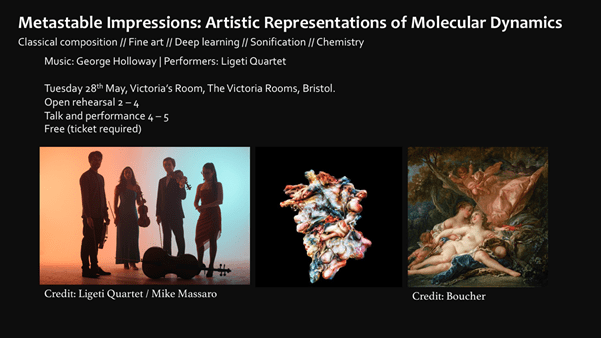
In addition to the sonification and string quartet we wanted to produce novel visual representations of the protein. To do this we used a technique called style transfer to impart style from paintings to more traditional representations of the protein. One example can be found on the flyer for the performance: 
The right-hand image is of a painting by the French artist Boucher and in the middle is a representation of the protein ‘in the style of’ Boucher.
The string quartet and visual representations of SETD8 were linked through a timeline of scientific thought loosely related to proteins, chemistry and statistical modelling. We highlighted five different scientists, corresponding to the five movements of Metastable, with contemporaneous (both geographically and temporally) artworks and composers. The five composers provided the musical style of each movement, while the five artworks provided the artistic style of the protein representations. Our final timeline was:
I. Medieval period, England
The scientist we chose was Roger Bacon for his work on developing the ‘scientific method’. The composer was Godric of Finchale and the art work was an illumination from the Queen Mary Psalter by an unknown illuminator.
II. 17th Century, England
The scientist we chose was Robert Hooke for his investigation of the microscopic world which was beautifully illustrated in his book Micrographia. The artwork we chose was an image of a flea from this work and the composer was Henry Purcell.
III. 18th Century, France
Our understanding of protein dynamics is, in part, statistical, so for that reason we chose a pioneer of statistics Pierre Simon Laplace as our scientist. The visual source material was Jupiter in the Guise of Diana and the Nymph Callistor by François Boucher and the composer was the prolific opera composer Jean-Philippe Rameau.
IV. 19th Century, Russia
Protein motion has the property of being ‘memoryless’ which means that its future motion isn’t determined by its past motion. Andrey Markov was a mathematician who studied this type of process. Russian contemporaries of Markov were the composer Modest Mussorgsky and artist Illya Repin, whose work Sadko gave us the fourth visual style.
V. 20th century, USA
Many of the advances in our understanding of Proteins came from the UK, such as Kendrew and Perutz (first protein structure determination by X-ray crystallography), and Dorothy Hodgkin (structure of vitamin B12 and insulin). However, we wanted to avoid more UK based scientists so we instead went for Berni Alder & Thomas Everett Wainwright for their work on simulating molecules and Frances Arnold whose Nobel prize winning work has given us novel ways for creating enzymes (a type of protein). The composer we chose was Morton Feldman whose work incorporated uncertainty and thus seemed natural to complement the statistical nature of protein motion. The artwork we chose is Gothic by Jackson Pollock, another prominent artist on the New York art scene along with Feldman.
The art works for each movement can be seen below:

Rob Arbon, animations and statistical modelling
My role in this project was twofold:
- to create the statistical model of the protein dynamics from the data provided by the Chodera lab
- produce animations of the protein in the style of the artists from the time line.
The statistical tool I used was a Hidden Markov Model (HMM) which takes multiple time-series of the protein and classifies them as belonging to a small number of distinct states (in our case five) called Metastable States. Protein motion can then be thought of as hopping from metastable state to metastable state. We took five representative time-series and used how the protein hopped from state to state as a structure for each movement of the string quartet.
In our previous work, Alex Jones and I had already worked out how and what information contained in the HMM to sonify and so we were able to use that framework to sonify this system.
To create the animations I used a technique called style transfer. This uses deep convolutional neural networks (CNN) which are used to classify images. We can ask ourselves (mathematically, of course) what a CNN considers the ‘style’ of an image. Below, I asked Google’s Inception CNN what it thought the style of the Boucher image was. 
On the left-hand side is the original image and on the right-hand side is the CNNs conception of ‘style’ at a particular point in the classification process. There are other points available which pick up different types of style not shown here. The style transfer algorithm takes this conception of style and blends it with arbitrary ‘content’ images. In this case our content images are the traditional representations of proteins. The image below shows this: 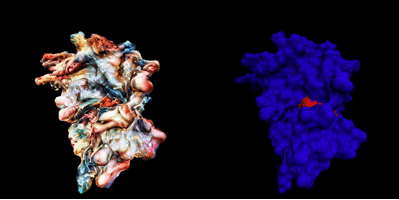
The right-hand image here is a content image – a traditional representation of a protein which shows the surface atoms of the protein only. The left-hand image is a blending of the pure Boucher style above and the content image. I did this for 10’000 still images of the protein and used these stills to create the animations accompanying the string quartet.
There were a number of challenges I faced in performing my part. The first was to find appropriate parameters of the statistical model which gave musical structures which were usable by George. The second was to find appropriate parameters of the style transfer process, most notably how to pre-process the images and what particular conception of style for each artwork to transfer over to the content image.
Alex Jones, sonification
My role was to create a faithful sonification of the protein dynamics using electronic musical synthesis. The primary aim of the sonification is to allow the listener to hear accurately the information being aurally displayed. This is in contrast to the string quartet which was primarily a piece of music ‘informed’ by the data.
In our previous work, Rob Arbon and I worked out which parameters of the HMM were most useful to represent and my expertise in sound engineering allowed us to map these to synthesized sounds which synchronised with traditional animations of the protein. In this way the user can see structural information while simultaneously hearing more abstract concepts of the protein such as its stability.
In this project the sound design was informed by my conversations which George on more traditional musical theory topics such as the harmonic series and chord inversions. The end result was a sonification of the data underlying the first movement of Metastable and is available at the project OSF repository.
There were a number of challenges in this project which needed to be overcome. The first being that the new harmonic language introduced by George was complex and mapping information to sounds became much more challenging than our previous sonification. The second major challenge was overcoming the language barrier between the classical and sound engineering worlds. We were both surprised however at how much common ground we shared once our respective nomenclatures and conventions had been explained.
George Holloway, composer, Department of Ethnomusicology, Nanhua University, Taiwan
I had a dual role in the project. The first was to work with Alex Jones on the sonification, to find readily audible musical structures that could meaningfully convey to an audience the aspects of the data we deemed to be relevant. In so doing, we had to consider not just the audibility, but also the listenability of the musical structures we chose. This naturally touches upon one’s individual judgement and taste, and so takes the sonification a step beyond the merely slavish translation of data into sound, into an aestheticised or crafted sonification. My second, and quite distinct role, was to compose a piece of music that was both data-sonification and an autonomous artwork— a sort of data-inspired music.
For both sonification and composition, the “legibility”, or more aptly, the audibility of the relationship between underlying data and heard result was crucial, but for subtly different reasons. The musical composition, while not in any way intended as a data-scanning tool like the sonification, and only weakly intended as a public science-communication tool, nonetheless is ineradicably bound to the underlying data. For the music to have a clear expressive purpose, one must be able to appreciate that there are processes of tension and change in the music evocative of the physical processes at work in the molecular dynamics. In the “Metastable Impressions” project this stricture was made even more acute by the combination of the music with a projected visualisation of the molecule. The music could not therefore be completely autonomous (freely treating the material in its own time and following its own development), but had necessarily to conform to the same time structure and transformations of material to which the visualisation conformed, as dictated by the underlying data.
There had to be some accommodation to aesthetic considerations at the stage of choosing the portions of data to be sonified (the “trajectories”): I proposed parameters to which the data should conform in order for it to be usable for generating musical material. Once Robert Arbon had selected trajectories according to these parameters, however, it was clear that the data would entirely preclude a “traditional” musical syntax and phraseology.
This influence of the data proved to be decidedly advantageous for me as the composer, and was perhaps the most valuable insight I gained from composing the piece: precisely because the time structures and repetitions of material dictated by the data precluded more expected “organic” development of the materials, the five movements that made up my piece Metastable naturally took on unexpected and spontaneous-feeling structures. The music felt elusive and yet not incoherent, at least to my mind.
One final aspect to mention is the use of style-transfer in both the visualisation (using machine-learning) and in the musical composition (done “manually” by me as the composer). In a sense, my stylistic use of earlier composers, such as Purcell and Mussorgsky, sits in a time-honoured tradition of musical borrowing known as “transcription”. The idea was that both visualisation and music would take on stylistic aspects of the time periods and locations related to important developments in the history of science that led to the present research into molecular dynamics. This in itself added an entirely other layer of aesthetic considerations to a complex but very rewarding project.
Dr Pete Bennett, project supervisor
I took a supervisory role in the Metastable Impressions project, attending the weekly meetings and overseeing the technical and artistic collaboration between Rob, George and Alex. Having a background in both computer science and music has been useful throughout the project as it has allowed me to fully appreciate the outstanding work done by the team and occasionally allowed me to act as a bridge when miscommunications arose during the meetings. I’ve particularly enjoyed the approach to interdisciplinary working that this project has taken, with the three disciplines of music composition, computational chemistry and sonification all playing an equal role in leading the project forward. At no point was there the feeling of one being held to have greater importance and dominating the discussion. Additionally it was great to see time and effort being taken throughout the project for complex terminology and theory to be explained in a simple manner to all team members.
The result of this project is hard to describe – a string quartet, playing a score based on molecular dynamic structure, musically influenced by both sonification techniques and the history of composition, accompanied by a visualisation that uses machine learning to transfer artistic styles from the history of chemistry. The difficulty of describing what was achieved arises from the fact that no single element takes precedent and overall is testament to the truly interdisciplinary nature of the project. Despite the difficulty of explaining the project on paper, the concluding performance brought together all of the strands together seamlessly into one clear artistic vision that was very well received by the audience, resulting in a deep debate that spanned all the disciplines involved.
The Jean Golding Institute seed corn funding scheme
The JGI offer funding to a handful of small pilot projects every year in our seed corn funding scheme – our next round of funding will be launched in the Autumn of 2019. Find out more about the funding and the projects we have supported.