
We are excited to announce the winner of the 2020 Food hazards from around the world data competition is Robert Eyre with his visualisation project ‘FSA related alert tracker’.
The Jean Golding Institute recently teamed up with the Food Standards Agency (FSA) for a data visualisation competition
The competition
Every day the Food Standards Agency receives alerts from around the world about food products that have been found to be hazardous to human health, from salmonella in chicken to undeclared peanuts to plastic in pickles. Sometimes these products make it to our shelves in the UK and have to be recalled or withdrawn. But with so much data on food hazards at our fingertips, we want to be proactive in identifying potential hazards to UK consumers, before anyone buys a hazardous product.
The FSA made a dataset of food alerts available and we asked for data visualisations that could help to understand how the dataset might alert us to food risks.
The winning project
The winner was Robert Eyre, PhD student, Department of Engineering Mathematics with his visualisation FSA related alert tracker.
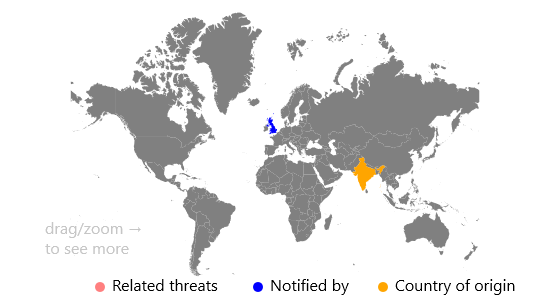
The visualisation is a dashboard that allows the FSA to identify threats that are related. Once an article about a threat has been chosen, you can see where on the map, and where in time related threats happened.
The idea behind the visualisation is to show the threats that had been reported in the United Kingdom, and that given a threat, it should show the other threats related to it. Once a threat has been selected from the left panel, the right panel will automatically update, showing the data source, a link to the data source and information about the incident, such as when the article was published, and what the incident is about. Then, the map will highlight the source of the threat, and the country that reported the threat.
To then show the related threats, there are a series of buttons under the left panel to decide what is classed as a related event. Once one of these buttons are selected, the map is updated to show the locations of the related threats (and roughly how many threats there are by the size of the new circles). This should show the FSA where specific threats are most common when related to the United Kingdom. Additionally, a time series is shown for the related events highlighted. Here the FSA could identify any peaks or dips, that they could then investigate further for events that may have happened.
The winner received £1000 in prize money
The runners up
Two runners-up each receiving £250 are Marina Vabistsevits & Oliver Lloyd and Angharad Stell.
Marina and Oliver received runner up for their visualisation, ‘Too much tooty in the fruity: Keeping food safe in a post-Brexit Britain’ A brief exploration of the UK’s reliance on the EU for food safety, and the related challenges that Brexit may bring.
Angharad received runner up for the visualisation ‘From a data space to knowledge discovery’ An interactive plotting app that allows exploration and visualisation of the dataset.
The Jean Golding Institute data competitions
We run a number of competitions throughout the year – to find out more take a look at Data competitions.
