
JGI Seed Corn Funding Project Blog 2022-2023: Holly Fraser
Introduction
Extracting information from free text sources is a complex and exciting data science challenge. Textual data generated by humans is rich, complex, with its meaning often contextual and packed with nuance. This project analysed data from Reddit, an online social news website and discussion forum community, using Natural Language Processing (NLP). NLP is a data science technique used to extract information from textual data sources. A particular aim of this project was to explore ways to model the types of discussions Reddit users were having about antidepressants (AD), a common intervention for the management of depression and anxiety symptoms.
Model exploration
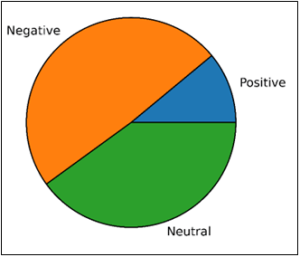
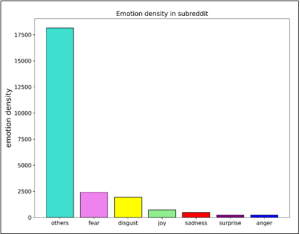
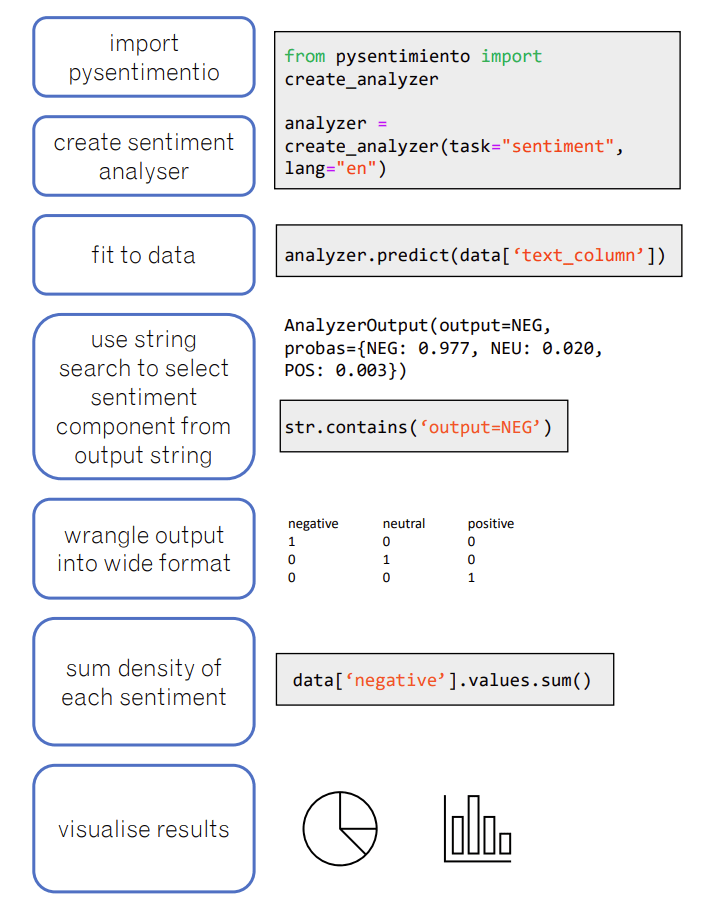
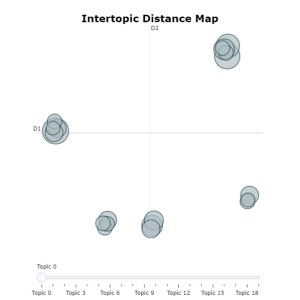
With support from the Jean Golding Institute (JGI), I was able to explore sentiment, emotion, and topics discussed on various subreddits using a range of data driven techniques. For example, I used a sentiment analysis package[1] to extract the sentiment (fig 1) and emotion (fig 2) from a large data corpus (n=24183) extracted from the r/antidepressants subreddit. Figure 3 depicts a schematic of the workflow used to analyse the sentiment of the comments on this subreddit. I then used topic modelling to extract and cluster the topics from the data corpus using a cluster based transformation technique[2] (fig 4).
It was really valuable to be able to use these techniques to explore questions related to the lived experience of managing mental health challenges. My PhD research involves using population health data to explore questions related to depression and medication use, so using free text data to explore similar questions in a data driven exploratory way was thought-provoking. For example, how do you extract specific information relevant to mental health from a real-life, unstructured dataset? How could we use data analysis like this for impactful mental health research?
Interpretation of results
One of the biggest challenges of the project has been interpretation of the model results. The output of the topic modelling was particularly difficult, due to many of the topics extracted containing words that didn’t have much meaning out of context despite using strategies to remove these ‘noisy’ words.
The results of the sentiment and emotion analysis are relatively easy to describe and interpret however – for example, the sentiment model classified the majority of comments as having a negative sentiment (fig 1). The emotion analysis model output is also relatively easy to interpret, but worth considering that the model struggled to classify the data into discrete emotion categories, with the ‘others’ column being the most densely populated (fig 2). This doesn’t seem like a surprising finding when looking at the raw data from a human perspective; many of the comments are long and complex, containing multiple stances. For example, the model struggled to correctly predict the emotion of comments which said things like ‘I was doing badly on X, but I’m doing much better now on Y’ (paraphrased). Therefore, more work evaluating the ability of the model to correctly classify things like sentiment and emotion would be valuable.
Knowing which types of text data the model struggled to classify gives an interesting insight into what the challenges of NLP are in this particular context, where the text data are often complex and comprised of different clauses containing multiple emotions.
Conclusion and next steps
A valuable next step to this work would be to more formally assess the ability of the models to classify sentiment, emotion, and extract topics on a smaller data set by using human interpretation. This would give an insight into how well the models I used perform on Reddit data, by comparing the model output to human judgement in a structured way. Extracting important information related to health (e.g., patient experience of a healthcare intervention) from unstructured text data is a significant NLP challenge; having better insight into the complexity of this challenge has been one of the most valuable outcomes of this project.
If anyone is interested in hearing more about this work or my other projects, you can find me on Twitter @hollyalexfraser or email holly.fraser@bristol.ac.uk.
Note: Work carried out for academic purposes only.
References
[1] J. M. Pérez, J. C. Giudici, and F. Luque, “pysentimiento: A Python Toolkit for Sentiment Analysis and SocialNLP tasks.” arXiv, Jun. 17, 2021. Accessed: Jun. 17, 2023. [Online]. Available: http://arxiv.org/abs/2106.09462
[2] M. Grootendorst, “BERTopic: Neural topic modeling with a class-based TF-IDF procedure.” arXiv, Mar. 11, 2022. Accessed: Jun. 17, 2023. [Online]. Available: http://arxiv.org/abs/2203.05794