Blog post by Chris McWilliams, Tamzin Whelan, Roberta Guerrina, Fiona Jordan, Amanda Williams.

Figure 1: (left) Tamzin scanning books, running them through the OCR software and correcting the output; (right) a child reading an early years book.
Children are strongly impacted by the gender messages they receive at a young age, and books are integral to this messaging. The goal of this project is to examine the prevalence of gender stereotypes in Early Years Foundation Stage (EYFS) book collections available in school classrooms.
Specific aims of the project include:
- To create a machine learning tool that will analyse both the gender of the protagonists (making a distinction between human and non-human characters) and the language associated with the different genders;
- Use an interdisciplinary perspective to analyse patterns revealed by word frequency extraction, to gain a better understanding of how EYFS children’s books are reinforcing or challenging gender stereotypes;
- To produce reusable software and data science methods that can continue to be used to identify the prevalence of gender stereotyping in book collections. The intended users are teachers, parents and researchers.
Results
Our sample consists of 200 books from the reception class of a primary school in rural Devon. As in most schools, the collection was amassed over time and the date of first publication ranges from 1978-2020. So far, 130 of the 200 books have been scanned and processed. Initial findings suggest that within this collection there is a disproportionate representation of genders and characters are depicted in gender stereotypical ways.
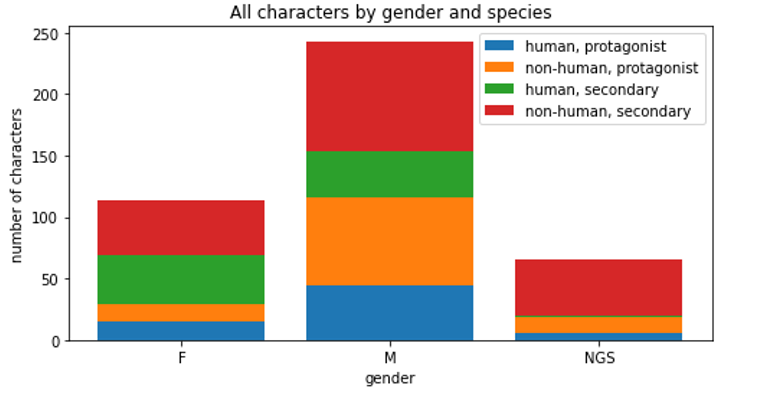
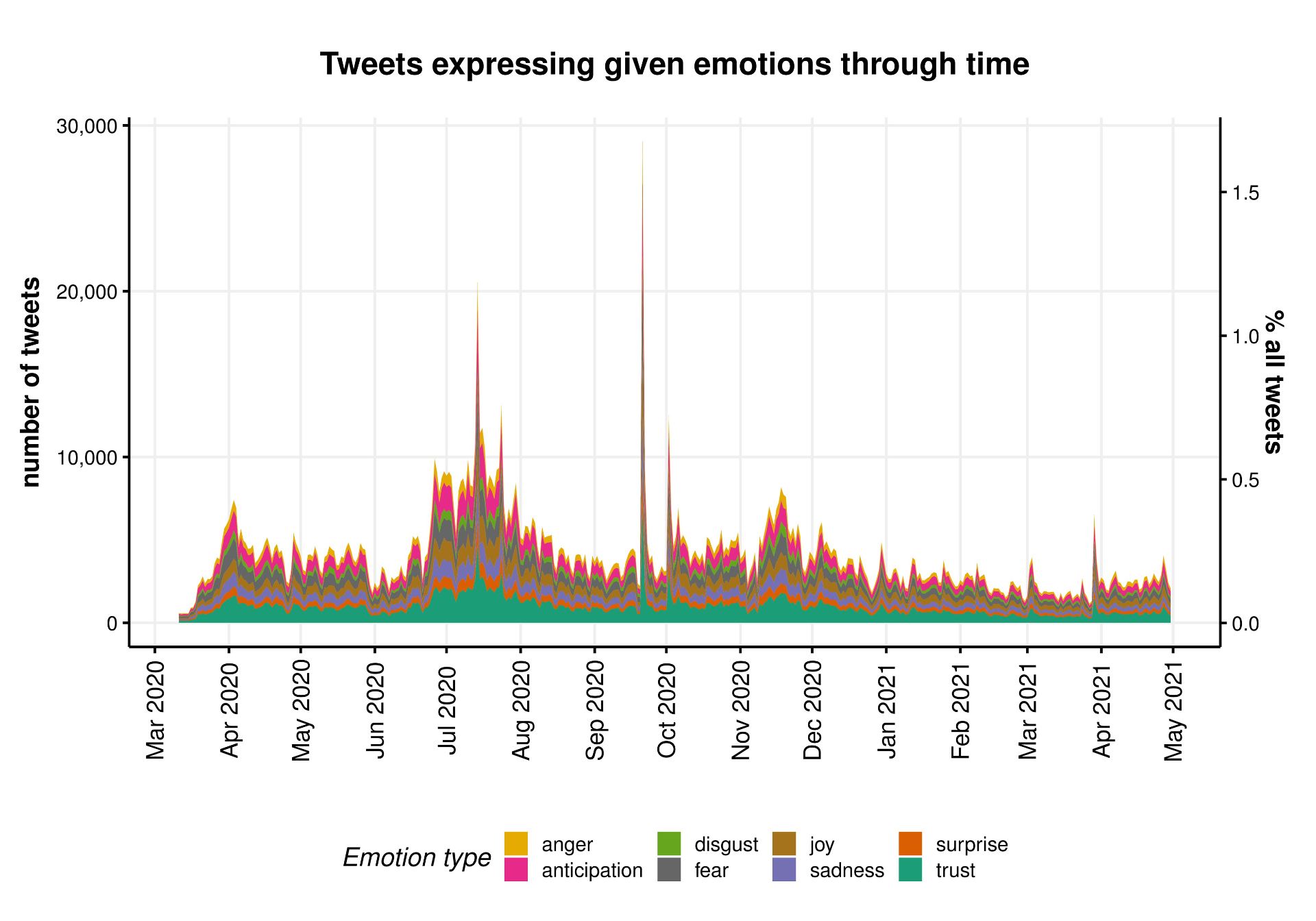
Figure 1. The frequency of gender (female [F], male [M], non-gender specific [NGS]) and ‘species’ (human/non-human) of protagonists and secondary characters from 130 children’s story books.
There are two key findings to date:
- Gender Representation. By coding the gender (female, male, or non-gender specific) and species (human or non-human) of the protagonist and secondary characters in each storybook we were able to examine whether the genders were equally represented.
Unsurprisingly, they were not. The results are depicted in figure 1. Male characters outnumbered female characters at a rate of more than 2:1 (32% female characters in total). When females were included, they were far more likely to be represented as secondary characters than protagonists (75% of females were secondary characters, versus 52% for males). This is important as it replicates the harmful stereotype of females occupying supporting roles.
2. Gender Stereotyping. Using Spacy to parse the sentence structure, we examined verb clauses where the noun-subject belonged to a standard list of female/male identifiers or was the name of a character with identifiable gender (manually coded).
From these sentences we then extracted the following words types and associated them with the gender of the noun-subject:
- the verb associated with the noun subject in each sentence (Root)
- nouns that are the object of the verb clause (Dobj)
- adjectives associated with the noun subject (Amod and Acomp)
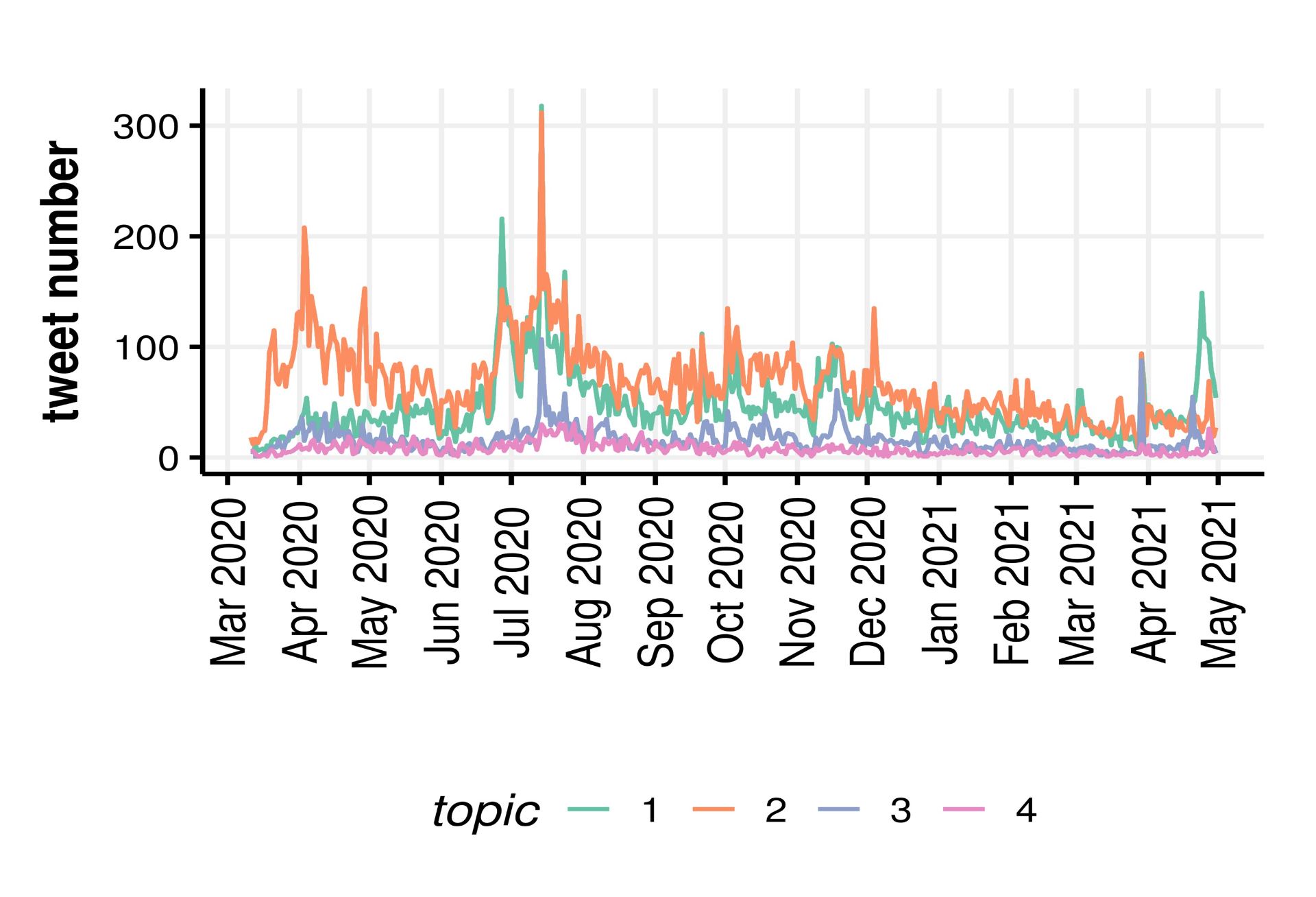
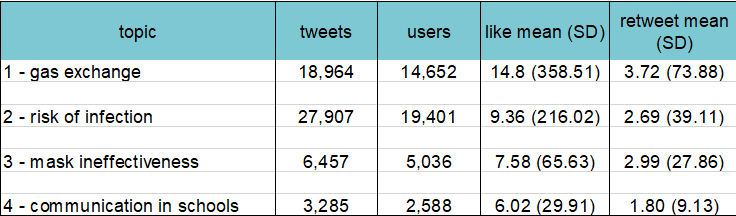
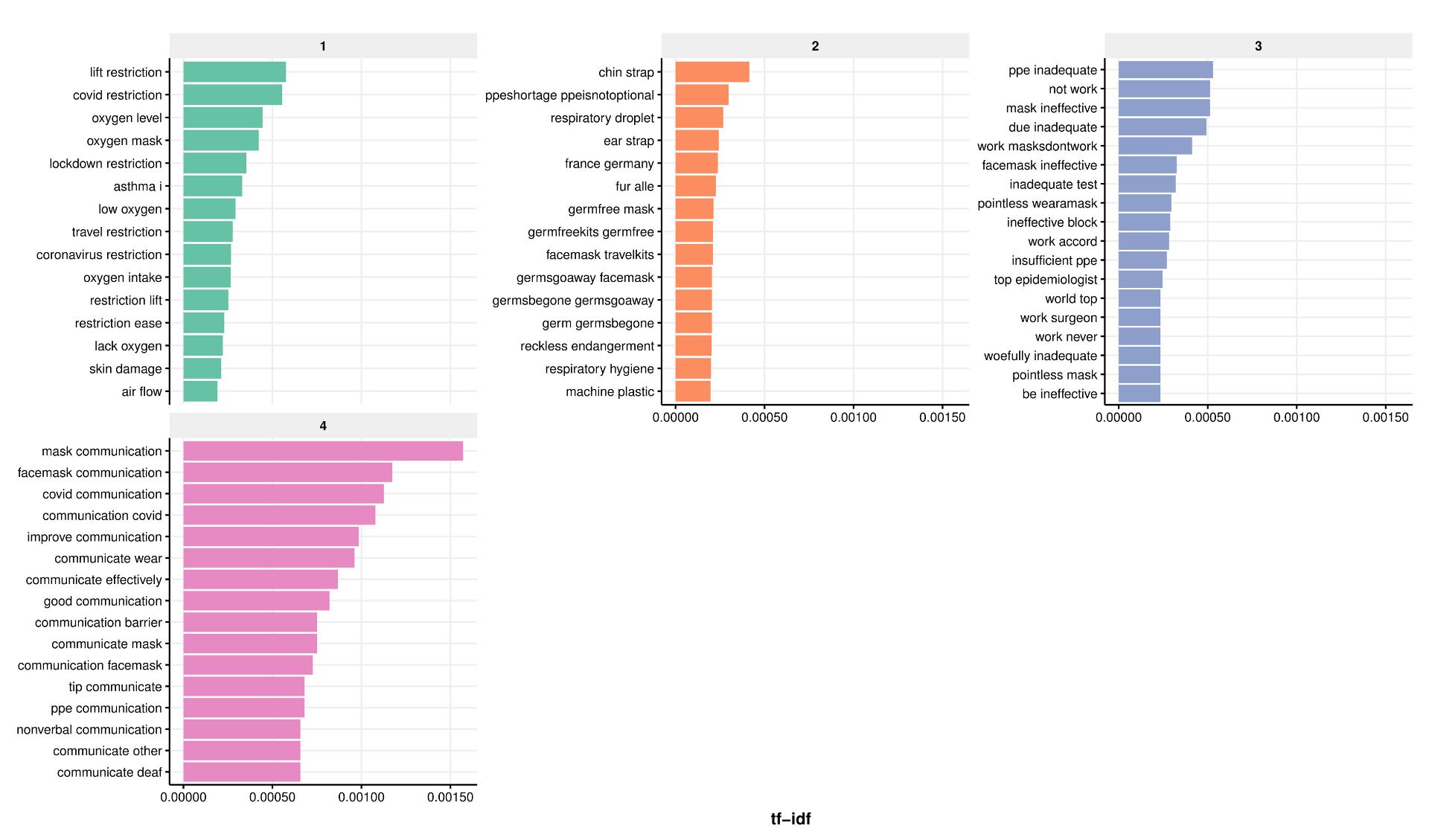
The results are summarised in figures 2 and 3, and in table 1 which shows that female characters have approximately half as many associated words across the three word types. This reveals a smaller vocabulary associated with female characters, suggesting that females are less relevant to plot lines and have less expansive narratives.

Figure 2: Word clouds showing the frequency of verbs associated with female and male characters.

Figure 3: Word clouds showing the frequency of nouns associated with female and male characters.
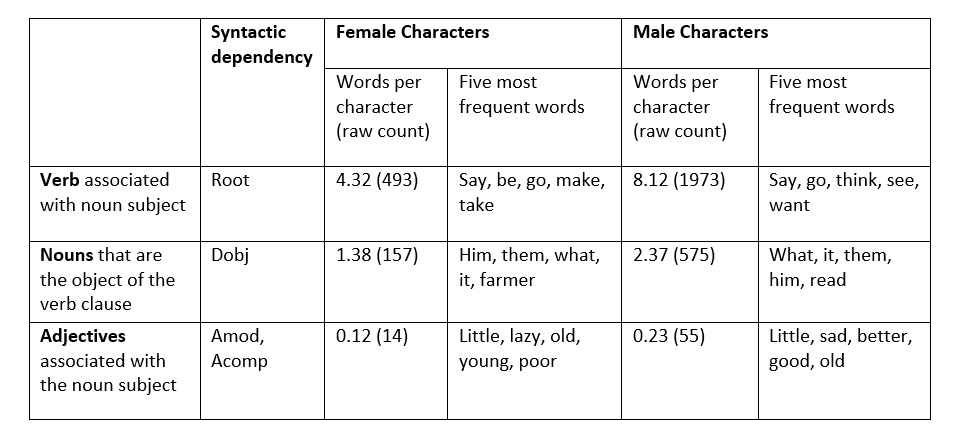
Table 1: Summary of word types associated with female and male characters. ‘Words per character’ is the average number of distinct words per character.
We are currently verifying the coding process, but initial findings demonstrate that gender stereotypes continue to be present in children’s literature. For example, verbs related to female characters are more passive, and verbs related to male characters are more active. Aligning with gender-based microaggressions, male characters tend to dominate the text, reaffirming masculinity as the norm. Female characters most frequently act on ‘him’ (table 1), indicating a centralisation of the male experience within the portrayal of female characters. Furthermore, females predominate in caring roles with 25% of all female characters written as Mum, compared to 4% of males as Dad. This reproduces stereotypical divisions between public and private roles, situating females in the domestic sphere and males in the external world.
In summary, we find that female characters are not being represented equitably in this collection. When female characters are featured, they are more likely have minor roles and are more likely to perform stereotypically female roles. Patriarchal socialisation at such an early age negatively impacts the way children understand society and their position within it. These findings demonstrate that through both the omission and portrayal of female characters, harmful gender stereotypes are indeed present in contemporary classroom libraries.
Future Plans
Encouragingly, there is increasing awareness that diversity and representation in children’s literature is problematic and some online resources and studies are drawing attention to this issue. In addition to expanding the dataset, developing the data science, and disseminating findings to academic audiences, we are keen to work with parents, teachers, and community partners to actually change what children are reading. This will be the foundation of a larger funding application – we look forward to updating the JGI community on our future successes in this area.
Please contact Chris McWilliams (chris.mcwilliams@bristol.ac.uk) for more information about the project.