

In the Spotlight on Data blog posts, the JGI interviews the owners of datasets available on the University of Bristol’s data.bris platform. We want to showcase the great research that goes on at the University and help bring people’s attention to datasets which could be reused in new and exciting ways.
If you missed it, be sure to check out the first blog post on the effect of glass markings on drinking rate in social alcohol drinkers.

In this, the second blog post, Natalie Thurlby, Data Scientist at the JGI, talks to Dr Rebecca Barnes about being a data steward of sensitive data, the benefits of sharing data, and what can be learned from patients’ interactions with their doctors. Our conversation is centred on the unique ‘One in a Million: A study of primary care consultations’ dataset.
Nat: Could you tell us a little bit about the dataset on data.bris?
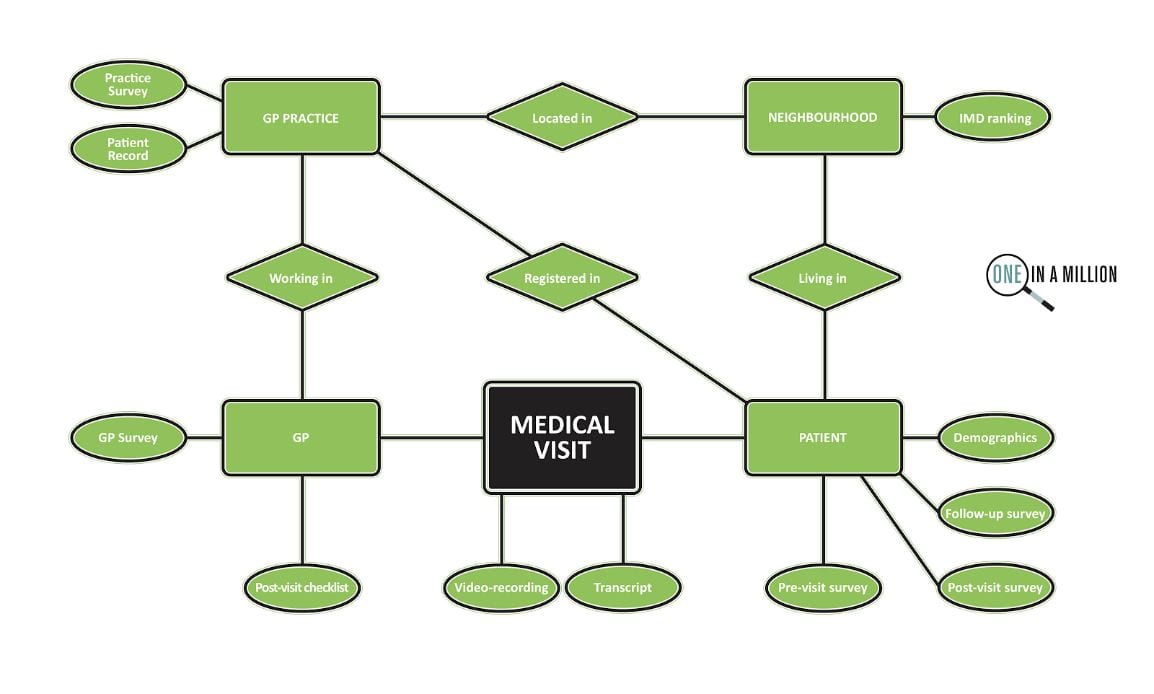
The One in a Million primary consultations archive came out of a study funded by the National Institute for Health Research School for Primary Care Research. The original study team consisted of myself and colleagues Chris Salisbury, Matthew Ridd and Marcus Jepson in the Centre for Academic Primary Care. The study was named ‘One in a Million’ because we know that around one million patients visit a GP every day in England, but not much is known about what actually happens during those visits. The dataset contains around 300 high quality video recordings of medical consultations with permissions for reuse, plus verbatim transcripts and linked demographic, survey data and medical record entries.
The video recordings were collected in Bristol and the surrounding area in twelve different GP practices – six in areas of high deprivation and six in areas of low deprivation. Across those practices, we recorded medical consultations between 23 different GPs and unselected adult patients – those who had an appointment at the practice on the day of filming and who were happy to take part. We received extra funds at the end of the study from the South West GP Trust that enabled us to code the consultations data for all the different problems and issues that were discussed. This has added considerable value to the dataset.
In addition to capturing the basic data on patient, GP, and practice characteristics, we asked patients to fill out three surveys: one immediately before they went in to see the GP, one immediately after they came out, and a follow-up survey ten days later. The GPs also filled out a survey for us and a brief checklist after each recording. We also have data about the information entered in the electronic health record, and any related future visits that patients made up to three months later.
Nat: Could you briefly explain how your research methods influenced the type of data that you collected?
I’m an applied conversation analyst which means that I work with recordings and detailed transcripts of naturally occurring talk between people – real life events as they happen – in my case medical encounters between patients / carers and health care professionals. This allows me to understand how the everyday tasks and goals of the medical consultation are jointly accomplished, and opens a window to the challenges and socio-medical dilemmas faced by professionals and patients along the way. This is different to working with say interview or focus group data, where people might talk about an event and what they remember happening.
I knew that this dataset would be of interest to anyone interested in communication in medical care and therefore wanted to make sure that the video recordings were the highest quality we could get. We used high definition cameras with wide angle lenses so as to capture all parties to the interaction. For an interaction researcher, when parties are co-present, video data is the ‘gold standard’ as it allows you to capture talk, bodily conduct and use of material and digital resources.
Nat: What was your initial research on the dataset and how does that link to your motivation for creating the dataset?
At the time I was interested in the different ways that GPs were recommending drug treatments to patients during medical visits. I needed to collect as many cases of routine treatment planning activity as possible, and to be able to see the extent to which patients were involved. I was working on a cross-national study with colleagues at UCLA comparing treatment recommending practices in US and UK primary care consultations. This work resulted in a Special Issue in Health Communication.
During the study we coded all the different types of treatment recommended. I noticed that there was a difference between drug treatment recommendations and self-care treatment recommendations. Self-care treatment recommendations were more likely to be delivered by GPs as optional and were less likely to receive clear acceptance from patients. At 10 days, patients were also less likely to recall a self-care treatment recommendation. We also compared how often self-care treatments were recorded in the medical record compared to drug treatments, and there was quite a disparity there, which is concerning since it removes the opportunity for GPs to follow up on how patients are getting on.
At the same time, a key motivation for the project was to set up the archive. One of the reasons I did this was to make medical consultations data available for other researchers who might really want to work with this kind of data, but might not be in a position to collect such a large dataset themselves. I’m very passionate about improving communication in medical care, and I didn’t want research on real consultations data to die out because of how difficult it is to collect the data.
Nat: How was the process of organising the collection of all of this data, given that it’s so sensitive?
Gaining a favourable NHS ethical opinion to do this felt like a huge challenge, but I love a challenge! I did a lot of work in advance researching whether anyone had done this kind of thing before, the ethical and legal issues of gaining consent for future reuse, and how to keep the data safe. We tried to strike a balance between making sure that we had really robust systems in place, to keep it safe, and supporting the data being reused for as many different projects as possible
During this time, I visited the UK Data Archive at the University of Essex who provide access to the UK’s largest collection of social and economic data. Luckily enough I met Debra Hiom (who now heads up

data.bris) there. Some time after, I was talking to her about what I was planning to do and she had just set up data.bris and it felt like that was the perfect place to keep it. We worked out the process in advance to make sure that access to the data would be controlled and appropriately managed. The dataset can only be used by bona fide researchers (no commercial use) with NHS ethical approval.
As a team, we wanted to enable the dataset to be useful to as a wide a range of researchers as possible. We surveyed some key people in UK academic primary care, asking them what sort of information and measures would be most useful to collect for a range of different projects.
Nat: Is there anything you’d like to share about the process of sharing research data?
I continue to feel inspired by sharing this data. There is the feel-good factor of being able to help other people access ‘hard to reach’ data, but I also think it’s the most ethical thing for researchers to do, not only for transparency, but also to maximise the value of the data. It takes a lot of planning, researcher time and money to collect, and can be quite burdensome for patients and health care professionals.
I’m also genuinely excited to see how other users are working with the data in different ways to answer different research questions. It’s a bit like having an extended family! The other really great thing for me as a researcher is that the datasets here are given their own DOI (Digital Object Identifier), so at some point in the future I’ll be able to track the impact. It’s been easy in the past not to think of data as a resource in that way.
The data.bris team have been fantastic. I really recommend them, they’ve been SO helpful!
Nat: Were there any particular challenges for you in working with this dataset?
We wanted to work with high definition video to maximise image quality, but of course that means huge file sizes. So learning about the best ways to transfer, store and process it was a bit of an eye opener, really.
To prepare it for reuse, we have had to go through every consultation and anonymise any mention of names, addresses, place names… (Nat: I bet that was a big task!) Yes! In fact, it’s partly still ongoing. So, we’ve had to upskill in terms of video editing and get a computer that’s robust enough to be able to manage those huge file sizes.
One thing that we’re doing is watermarking any videos that we release to researchers with a unique user ID, which makes releasing the data feel that bit safer. It’s quite time consuming to watermark every video before we release them to people, but the videos are our precious cargo.
Nat: On the last Spotlight on Data blog post I highlighted how data.bris could be used to store open data, and obviously that’s not appropriate for this dataset. Could you explain what about the data.bris archive made it a good choice for a dataset like yours?
Every request usually comes to me first, so I get to talk to prospective users and make sure we have what they need to answer their research question. If their proposal is funded they put in a formal request that is independently scrutinised by the University Data Access Committee. To help protect our participants, we also built in that if anyone else wanted to use it, then they’d have to have an NHS ethics approval in place and we also knew that we’d have a Data Access Agreement which an institutional signatory would have to sign to keep the data safe (agreeing that they’d only use the data for what they specified in their ethics application and to agree to our conditions of use etc).
Because the participants have already given consent to reuse, further NHS ethical approval to use the archive is by proportionate review (a shorter and quicker process). We’ve been up and running for a number of years and I’m happy to say that every ethics application for reuse so far has been successful.
Nat: What’s the timeline or process for getting access to the data, for anyone who might be interested?
They should email me at the dedicated email address for the archive (one-in-a-million@bristol.ac.uk), I can then search the data to figure out if we can help them. So, for example, I can see how many relevant recordings we might have in the dataset for that particular area, and let them know if anyone’s already done or is doing the same thing. I also write them a letter of support for their grant application and they can cite our data paper.
The longest part of the process is usually them getting their funding, but after they’ve got that they put in their ethics request, and that can be turned around within a couple of weeks.
Then they put in a request online via data.bris, and show proof of ethical approval and their project protocol. The data access committee reviews the application, and since they’ve done a number of applications for our dataset now, that usually goes quite smoothly.

Nat: How has the dataset been used so far?
It’s been used by a number of people from different countries and backgrounds, who are at different stages of their academic career including PhD students, trainee clinicians coming into academia for short projects, and established non-clinical academics. We’ve got around twelve current users at the moment doing a really wide range of studies and we continue to have new interest. In the last month, we’ve had three new requests, so I think word is really getting around!
We also sought permission from our participants to use the data for teaching. I’m already using it for a course that I teach, and we’re hoping to be able to use the dataset as a resource for teaching undergraduate students in Bristol Medical School, creating anonymised vignettes from real cases, which we think will make a difference to their learning.
Nat: What’s next for the dataset?
Right from the start, I always hoped that we would grow the archive to include other types of primary care encounters. I’m currently working on a new study about the management of common infections in out-of-hours (rather than in-hours) primary care, and hope that participants will be willing for us to deposit some of this new data in the archive. That’s really interesting data because it takes place on the telephone, in primary care centres and in patients’ homes, and will include recordings of encounters with a wider range of health professionals such as nurses, paramedics and pharmacists. We begin data collection in March.
Nat: Do you have a dream future use for or collaboration for the data that you’d like to see happen in the future?
One thing I’d really like, that I was hoping at the beginning, is that it would enable international comparative studies and we’re getting closer to that. We’ve inspired a number of other people in other countries to collect similar data and we’ve shared a lot of our processes to enable other people to do that.
Myself and Barbara Caddick who supports the archive, have also become really interested in ways which we can engage the public with our data and we’ve just started to explore the possibilities of working with arts practitioners to enable that. We’ve done some initial scoping work with a composer called Jenny Bell, who works with fragments of transcripts from recorded interviews to build a cappella pieces of music. We want to build a small piece, representing our common shared experience of going to see the doctor. We’d like to incorporate some of the familiar ambient sounds of the doctors: the blood pressure cuff being pumped up, the beep of the thermometer… Then it could perhaps be shared on the radio, or as a physical performance, maybe even in waiting rooms!
Nat: How interdisciplinary has the research been so far and are there any schools or faculties that you’d like to collaborate with more?
So far, it’s been health-related, either clinicians or social scientists, but I’m excited about all the possibilities. We have had some interest from people working in AI, but up to this point they’ve been commercial companies rather than researchers, so we haven’t been able to do that yet. I’d like to attract some more data nerds! One thing that’s been untapped is looking at the non-verbal communication. That would be really exciting to have a look at.
We’ve just recently got some funding from the Brigstow Institute on a project with Genevieve Lively from the Dept. of Classics and Ancient History here at the University of Bristol looking at patient narratives and we’ll be working with a storyteller as part of that work.
Nat: And if anyone wants to get in contact with you, to talk about possible collaborations or uses of the dataset, how can they get in touch?
They can contact me at one-in-a-million@bristol.ac.uk and I’ll be happy to tell them more about the dataset and answer any questions. They can also find more information here:
In the next Spotlight on Data, Dima Damen will tell us about a unique egocentric video dataset of people cooking in their homes, EPIC KITCHENS.